![]()
![]()
![]()
![]()
2021-02-22

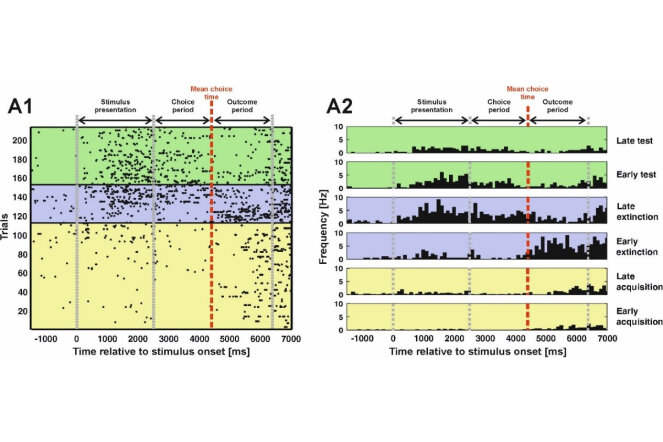
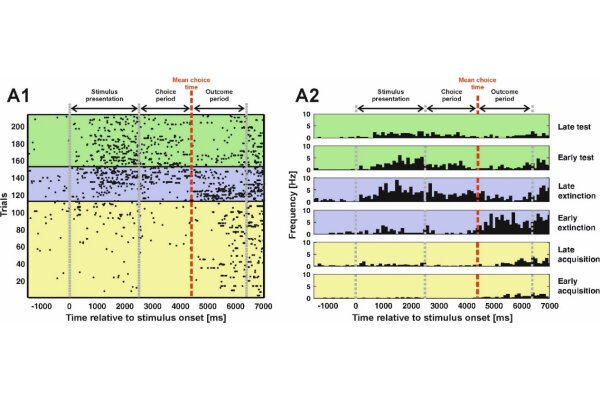
The ability to learn fundamentally rests on the prediction of events in the environment. If there is a mismatch between one’s expectations and the actual outcome, we are programmed to update our expectations based on reality. This process is known as reward prediction error-based learning and has successfully explained behavior in a large variety of species. On the neural level, the activity pattern of dopamine neurons in the midbrain has been identified to represent these reward prediction errors. However, only little is known about the precise temporal dynamics of reward prediction errors to this day. In our study, we investigated pigeons in an extinction learning paradigm that encompassed acquisition, extinction and a renewal test phase in a single session allowing for the investigation of single unit activity across learning. We found that neurons in the NCL, a structure strongly innervated by midbrain dopamine neurons, encode reward prediction errors both during the extinction phase as well as the renewal test. Gradually, the reward prediction error signal decreased with ongoing learning indicating the increasing match between expectations and reality. Furthermore, the neural signal transitioned from the outcome phase of the experiment to the presentation of the reward predictive cue. This is in line with temporal-difference models of learning. In total, our results show that reward prediction errors change gradually on a trial-by-trial basis during learning. Finally, we could demonstrate that reward prediction errors are truly expectancy-driven as we could elicit these signals without changing the quantity or quality of reward.
Packheiser, J., Donoso, J. R., Cheng, S., Güntürkün, O. and Pusch, R.. Progress in Neurobiology, https://doi.org/10.1016/j.pneurobio.2020.101901
The ability to learn fundamentally rests on the prediction of events in the environment. If there is a mismatch between one’s expectations and the actual outcome, we are programmed to update our expectations based on reality. This process is known as reward prediction error-based learning and has successfully explained behavior in a large variety of species. On the neural level, the activity pattern of dopamine neurons in the midbrain has been identified to represent these reward prediction errors. However, only little is known about the precise temporal dynamics of reward prediction errors to this day. In our study, we investigated pigeons in an extinction learning paradigm that encompassed acquisition, extinction and a renewal test phase in a single session allowing for the investigation of single unit activity across learning. We found that neurons in the NCL, a structure strongly innervated by midbrain dopamine neurons, encode reward prediction errors both during the extinction phase as well as the renewal test. Gradually, the reward prediction error signal decreased with ongoing learning indicating the increasing match between expectations and reality. Furthermore, the neural signal transitioned from the outcome phase of the experiment to the presentation of the reward predictive cue. This is in line with temporal-difference models of learning. In total, our results show that reward prediction errors change gradually on a trial-by-trial basis during learning. Finally, we could demonstrate that reward prediction errors are truly expectancy-driven as we could elicit these signals without changing the quantity or quality of reward.
Packheiser, J., Donoso, J. R., Cheng, S., Güntürkün, O. and Pusch, R.. Progress in Neurobiology, https://doi.org/10.1016/j.pneurobio.2020.101901
Copyright © BioPsy 2023
Last update: Sep 22, 2023
{kind=link}
{kind=link}
{kind=link}
{kind=link}